
Hold onto your neural networks, fellow AI enthusiasts. What if I told you the biggest AI breakthrough this year isn’t another trillion-parameter model? It’s a memory operating system from Chinese researchers that just solved one of AI’s oldest limitations: persistent, human-like recall. Meet MemOS—a paradigm shift that could redefine how LLMs learn, reason, and evolve. Let’s dissect why experts are calling this the missing link toward AGI.
The Memory Silo Problem: Why Current AI Feels Like Groundhog Day
Imagine explaining your gluten allergy to ChatGPT in a Monday chat, only to have it recommend pasta on Tuesday. Frustrating? That’s the “memory silo” crisis plaguing modern AI. Today’s LLMs treat conversations as isolated events. They’re brilliant stateless calculators but amnesiac agents. Here’s why:
- Parametric memory (weights frozen post-training) can’t integrate fresh insights without costly retraining.
- Retrieval-Augmented Generation (RAG) grabs external data mid-chat but forgets everything afterward—like scribbling notes on evaporating paper.
- No lifecycle control: Preferences, behavioral patterns, or evolving knowledge decay between sessions.
This isn’t just a UX nightmare. It blocks continual learning, personalization, and long-horizon reasoning—cornerstones of human-like intelligence.
MemOS Unveiled: An OS for AI Memory, Inspired by the Human Brain
MemOS isn’t a patch—it’s a full-stack reimagining of memory management. Led by Shanghai Jiao Tong University and Zhejiang University, the team treated memory like CPU or storage in traditional OSes: a schedulable, shareable resource. But the real genius? Mimicking the human brain’s memory hierarchy.

Core Architecture: MemCubes and the Three-Layer Brain
MemOS mirrors the brain’s neocortex-hippocampus dialogue via a three-layer stack:
- Interface Layer (API Cortex): Handles memory read/write requests like sensory input.
- Operation Layer (MemScheduler): The “prefrontal cortex” deciding which memories to activate, compress, or discard based on recency/frequency.
- Infrastructure Layer (Hippocampal Storage): Manages MemCubes across hot (RAM-like), warm (SSD-like), and cold (deep storage) tiers.
MemCubes—the atomic memory units—are revolutionary. Each Cube encapsulates:
- Content (text, embeddings, parameters)
- Metadata (provenance, versioning, permissions)
- Lifespan rules (e.g., “expire after 90 days unless accessed”)
Like neurons forming engrams, MemCubes compose, migrate, and evolve. A dietary preference mentioned casually could fuse with restaurant ratings into a personalized cuisine profile—persisting across sessions.
The KV-Cache Injection: 94% Latency Reduction
Here’s the engineering marvel: MemOS’s KV-cache memory injection slashes time-to-first-token latency by 94%. How? By bypassing traditional retrieval bottlenecks and injecting pre-computed context directly into the attention mechanism. Translation: faster recalls, fewer hallucinations.
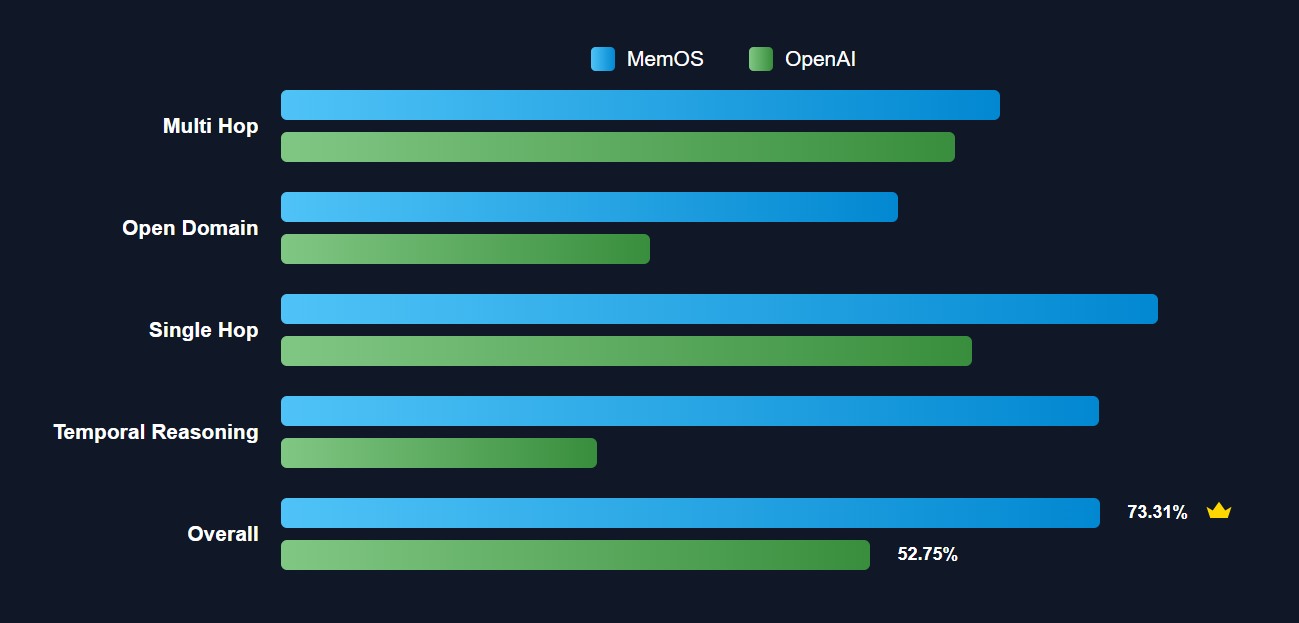
Performance: 159% Gains in Temporal Reasoning and Beyond
MemOS didn’t just edge past competitors—it demolished them. On the LOCOMO benchmark (testing memory-intensive reasoning):
- 159% improvement in temporal reasoning vs. OpenAI’s memory system
- 38.98% overall performance gain across multi-hop QA, personalization, and consistency tasks
Why such leaps? MemOS enables what researchers call “Mem-training”—where LLMs convert experiences into structured memory instead of drowning in context windows.
Enterprise Magic: Breaking Memory Islands and Building Marketplaces
Cross-Platform Memory Migration
Today, a customer persona built in ChatGPT dies when switching to Claude. MemOS shatters these “memory islands” via portable MemCubes. Marketers, analysts, or doctors retain context across tools—finally enabling continuous AI workflows.

Paid Memory Modules: The App Store for Expertise
“A physician could package diagnostic heuristics for rare diseases into a MemCube. Medical students install it, giving their AI assistant expert-level recall.”
Imagine a marketplace where:
- Legal firms buy “Supreme Court Rulings 2025” MemCubes
- Engineers subscribe to “AWS Optimization Patterns” updates
- Memory royalties create new revenue streams for knowledge workers
The AGI Accelerant: From Amnesiac Bots to Lifelong Learners
MemOS isn’t just about convenience—it’s a bridge to Artificial General Intelligence (AGI). Human intelligence hinges on accumulating and recontextualizing experiences. MemOS enables this for AI through:

- Continual learning: MemCubes evolve via new interactions, avoiding catastrophic forgetting.
- Self-directed memory: Models decide what to remember, how to compress it, and when to retrieve it—akin to metacognition.
- Cross-model memory sharing: Future versions could let LLMs exchange MemCubes, creating collective intelligence.
Recent neuroscience underscores why this matters: LLMs trained with next-sentence prediction (NSP) already mimic human brain patterns during discourse processing. MemOS adds the long-term memory architecture our brains natively have.
Get Your Hands Dirty: Open-Source, Free, and Production-Ready
Ready to experiment? MemOS is live and open-source:
- GitHub Repo: Full code/docs for integration
- Platform Support: Hugging Face, OpenAI API, Ollama—Linux first, Win/macOS soon
- Cost: $0. The research is free; paid modules may emerge later.
Deploying? Hook MemOS into your RAG pipeline to add memory lifecycle control. Start with short-term user preference tracking, then scale to complex knowledge graphs.
The Verdict: More Transformative Than Another 10x Larger LLM
MemOS isn’t an incremental update—it’s the foundation for stateful, empathetic, and adaptive AI. While Google and OpenAI bolt memory onto existing models, this team rebuilt memory as a first-class citizen.
For experts: This validates that architecture > scale. MemOS’s 159% reasoning gains came from smarter design—not more parameters.
For the industry: Prepare for AI that remembers you, evolves with you, and shares expertise across ecosystems. The trillion-dollar personal AI market just got real.
🔗 Dive Deeper:
MemOS Paper on arXiv
MemOS GitHub Repository
MemOS Official Docs
What’s your take? Will memory management be the next GPU-scale market? Drop your thoughts below. 👇