Vous vous demandez comment transformer votre grand modèle de langage (LLM) d’un simple bon élève à une véritable machine de raisonnement ? Bienvenue au Jour 2 : Le Fine-Tuning par Renforcement d’OpenAI, une approche révolutionnaire pour améliorer les capacités décisionnelles de votre modèle et l’aligner avec des intentions humaines. Dans ce guide, nous allons explorer le fine-tuning par renforcement, son fonctionnement, et pourquoi cette méthode est essentielle pour les développeurs cherchant à faire évoluer leurs applications basées sur l’IA.
Avant de plonger dans le vif du sujet, imaginez ceci : votre modèle est déjà impressionnant dès le premier jour – capable de répondre à de nombreuses requêtes et de générer du texte cohérent. Mais, au Jour 2, grâce à un affinage méticuleux utilisant le Fine-Tuning par Renforcement (RFT), il peut gérer des tâches complexes et spécifiques avec une finesse qui le distingue des modèles standards. Cet article vous expliquera le processus de fine-tuning, vous montrera des exemples concrets, et vous dévoilera comment le fine-tuning par apprentissage par renforcement peut transformer votre flux de travail. Allons-y !
Qu’est-ce que le Fine-Tuning par Renforcement (RFT) ?
Quand on parle de grands modèles de langage, des termes comme fine-tuning de modèle ou ajustement de modèle en apprentissage machine reviennent souvent. En bref, le fine-tuning consiste à adapter un modèle pré-entraîné pour une tâche ou un domaine spécifique, transformant un bon généraliste en un excellent spécialiste. Mais le Fine-Tuning par Renforcement (RFT) va encore plus loin.
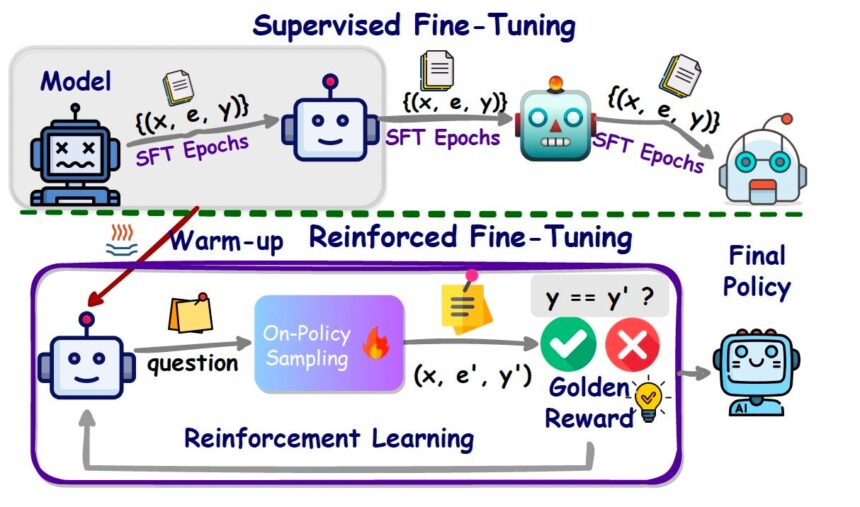
Au lieu de simplement ajuster les paramètres avec des données statiques (comme dans le fine-tuning supervisé), le RFT utilise des principes d’apprentissage par renforcement pour guider le comportement du modèle. Plutôt que de se limiter à des exemples prédéfinis, il interagit avec un système de récompense qui encourage de meilleures réponses et pénalise les raisonnements erronés. Résultat ? Un modèle qui assimile des retours nuancés et s’améliore grâce à des cycles d’optimisation itératifs. Imaginez enseigner à un élève non pas en lui faisant mémoriser des réponses, mais en récompensant des réflexions perspicaces et des stratégies de résolution constructives.
Jour 2 : Le Fine-Tuning par Renforcement d’OpenAI – Comprendre les Fondations
Pourquoi « Jour 2 » ? Si le « Jour 1 » correspond au pré-entraînement – où le modèle acquiert une vaste connaissance linguistique à partir de corpus massifs – alors le « Jour 2 » est l’application du Fine-Tuning par Renforcement d’OpenAI pour transformer cette connaissance en une expertise pointue. Prenons un modèle bien entraîné (comme le modèle O1 d’OpenAI). Au Jour 1, il est capable mais générique. Après le Jour 2, grâce au RFT, il devient plus qu’un simple réservoir de connaissances : il devient un raisonneur ultra-efficace adapté à vos besoins précis.
Le pipeline typique ressemble à ceci :
- Pré-entraînement : Le modèle apprend des schémas linguistiques généraux via un apprentissage auto-supervisé.
- Fine-Tuning Supervisé (SFT) : Le modèle affine sa compréhension à l’aide de données étiquetées de haute qualité.
- Fine-Tuning par Renforcement (RFT) : Le modèle s’améliore davantage en interagissant avec un modèle de récompense qui fournit des retours sur ses réponses, le guidant vers des productions plus précises et contextuelles.
Comment fonctionne le Fine-Tuning : Les Principes de Base
Pour comprendre comment fonctionne le fine-tuning, voici une explication pas à pas :
- Commencez avec un Modèle Pré-entraîné : Utilisez un grand modèle de langage (LLM) généraliste qui a déjà appris la grammaire, les faits, et les schémas à partir d’un vaste ensemble de données.
- Définissez la Tâche ou le Domaine : Identifiez le comportement spécialisé que vous souhaitez obtenir. Cela peut être le raisonnement médical, la rédaction de documents juridiques, les mathématiques complexes ou l’assistance au développement logiciel.
- Fine-Tuning Supervisé (SFT) : Fournissez des exemples soigneusement préparés d’entrées et de sorties souhaitées. Le modèle ajuste ses paramètres pour reproduire ces schémas, assurant un niveau de base pour le nouveau domaine.
- Fine-Tuning par Renforcement (RFT) : Introduisez un mécanisme de récompense – souvent alimenté par des principes d’apprentissage par renforcement pour le fine-tuning des LLM. Un modèle de récompense évalue les réponses et le modèle ajuste ses paramètres pour produire des résultats mieux notés.
Le Processus de Fine-Tuning : Guide Détaillé
Le processus de fine-tuning se déroule comme une symphonie bien orchestrée :
- Collecte et Préparation des Données : Constituez un ensemble de données adapté à votre tâche cible. Par exemple, pour un assistant de codage, rassemblez des extraits de code, des explications et des questions-réponses spécifiques au langage et aux frameworks que vous ciblez.
- Fine-Tuning Supervisé (SFT) : Entraînez le modèle sur ces exemples. Il apprend à mapper des entrées spécifiques à des sorties souhaitées. À ce stade, le modèle s’aligne déjà sur votre domaine, mais il peut encore nécessiter des ajustements pour gérer des cas inattendus.
- Construction du Modèle de Récompense : Créez ou choisissez un modèle capable d’évaluer les réponses du modèle principal. Cela peut être un autre modèle ou un système heuristique qui attribue des scores en fonction de la cohérence, de la précision et du respect des préférences utilisateur.
- Fine-Tuning par Renforcement (RFT) : Avec un mécanisme de scoring en place, le modèle principal « interagit » avec le modèle de récompense. Après avoir généré une réponse, il reçoit une note. Ce feedback façonne son comportement futur via des techniques comme l’Optimisation de Politique Proximale (PPO), un algorithme populaire en apprentissage par renforcement.
- Amélioration Itérative : Au fil des cycles d’entraînement, le modèle affine ses représentations internes, devenant de plus en plus performant face aux requêtes complexes.
Citation Inspirante :
« Le Fine-Tuning par Renforcement (RFT) permet aux développeurs de façonner le comportement des modèles avec précision et efficacité. »
Exemples Concrets de Fine-Tuning dans des Scénarios Réels
Besoin d’exemples de fine-tuning pour mieux comprendre son impact ? Voici quelques cas pratiques :
- Rédaction de Documents Juridiques : En appliquant les principes du fine-tuning en apprentissage machine, vous pouvez adapter un grand modèle de langage pour produire des documents juridiques bien structurés. Entraînez-le d’abord avec des contrats et des cas juridiques via le SFT, puis appliquez le RFT pour l’orienter vers le respect constant des directives juridiques. Résultat : des sorties conformes aux normes légales, réduisant le besoin de relectures coûteuses.
- Raisonnement Mathématique : Vous souhaitez un modèle capable de résoudre des problèmes mathématiques complexes de manière fiable ? Entraînez-le sur des ensembles de données mathématiques via le SFT, puis appliquez le RFT avec un modèle de récompense qui évalue la précision des solutions. Avec le temps, le modèle intègre des stratégies de résolution robustes et renforce son raisonnement mathématique.
- Assistance en Codage : Un modèle spécialisé dans le développement logiciel peut aider à déboguer, générer du code et utiliser des API. Après l’avoir affiné avec un ensemble de données contenant des extraits de code et des explications, utilisez des boucles de feedback basées sur le RFT pour encourager la génération de code efficace, adapté aux cas particuliers, et conforme aux standards de votre équipe.
L’Apprentissage par Renforcement pour le Fine-Tuning des LLM : Les Algorithmes Clés
Le fine-tuning des LLM via l’apprentissage par renforcement repose souvent sur des algorithmes d’optimisation de politiques. L’un des plus connus est le PPO (Proximal Policy Optimization). Pourquoi est-il si efficace ?
- Optimisation Stable : PPO limite les mises à jour pour éviter que le modèle ne s’écarte trop après une seule étape d’entraînement.
- Alignement Amélioré : En se basant continuellement sur les retours du modèle de récompense, le PPO guide le modèle vers des réponses plus pertinentes et alignées sur les attentes des utilisateurs.
- Contrôle Précis : PPO et des approches similaires offrent un équilibre entre exploration (essayer de nouvelles stratégies) et exploitation (se concentrer sur les stratégies efficaces).
Quand les développeurs évoquent le fine-tuning d’un LLM avec l’apprentissage par renforcement, ils font souvent référence à des applications de PPO ou d’approches similaires. En essence, il s’agit de guider un modèle, riche en connaissances générales, pour en faire un assistant fiable et contextuellement pertinent.
Comparaison entre le Fine-Tuning par Renforcement et les Méthodes Traditionnelles
Vous vous demandez comment le fine-tuning par renforcement se compare aux méthodes classiques ? Le fine-tuning supervisé (SFT) repose uniquement sur des exemples statiques, enseignant au modèle à reproduire des schémas existants. Cette méthode peut offrir des améliorations significatives, mais elle atteint rapidement ses limites. Que se passe-t-il si le modèle rencontre des situations absentes de l’ensemble d’entraînement ?
Le RFT dépasse cette limitation. Au lieu d’un apprentissage passif, il engage le modèle dans une boucle dynamique de feedback. Le modèle ne se contente pas d’apprendre ce qu’on lui fournit ; il apprend à partir de la qualité de ses réponses. Cette interaction active affine ses capacités de raisonnement, lui permettant de s’adapter à des défis imprévus et de fournir des réponses plus précises et riches en contexte.
Meilleures Pratiques pour le Fine-Tuning avec l’Apprentissage par Renforcement
Prêt à vous lancer dans le fine-tuning d’un LLM avec l’apprentissage par renforcement ? Voici quelques conseils :
- Commencez avec des Bases Solides : Assurez-vous que votre modèle pré-entraîné et vos ensembles de données SFT sont de haute qualité. Une bonne base simplifie le processus de RFT.
- Mesurez les Progrès de Manière Itérative : Suivez des métriques comme la précision, les scores de satisfaction utilisateur ou des KPI spécifiques à votre domaine après chaque cycle d’entraînement. Cela vous aidera à déterminer les stratégies les plus efficaces.
- Affinez votre Modèle de Récompense : Le modèle de récompense est au cœur du RFT. Si ses scores sont trop stricts ou trop indulgents, votre LLM risque d’apprendre des comportements biaisés. N’hésitez pas à ajuster ce modèle si nécessaire.
- Équilibrez Exploration et Exploitation : Laissez le modèle essayer de nouvelles approches, tout en surveillant attentivement. Des vérifications automatisées peuvent éviter que l’exploration ne mène à des comportements indésirables.
- Répétez le Processus : Le RFT n’est jamais « fini ». Chaque cycle d’entraînement offre des insights qui guideront les améliorations futures, perfectionnant progressivement les capacités du modèle.
Citation Inspirante :
« Le RFT, c’est comme entraîner un chef : au lieu de mémoriser des recettes, le chef apprend en goûtant, améliorant chaque plat jusqu’à ce qu’il soit parfaitement assaisonné. »
Gains de Performance et Efficacité
Au-delà de l’alignement, le RFT peut rendre vos modèles plus efficaces. L’approche basée sur les retours nécessite souvent moins d’exemples d’entraînement que des ensembles supervisés massifs. Cette efficacité se traduit par des économies de coûts et des cycles d’itération plus rapides. En outre, le RFT peut permettre de produire des modèles plus petits et plus rapides sans compromettre les performances. Lorsqu’un modèle apprend à raisonner plutôt qu’à simplement mémoriser, il peut offrir des réponses plus ciblées et réduire les temps d’inférence.
Intégrer le RFT dans Votre Flux de Travail
Vous avez déjà une pipeline pour entraîner vos modèles ? Intégrer le RFT est un processus relativement simple si vous suivez ces étapes :
- Pré-entraînement : Commencez avec un grand modèle de langage généraliste pré-entraîné.
- Étape SFT : Spécialisez-le pour votre domaine en utilisant un ensemble de données étiqueté.
- Phase RFT : Introduisez un modèle de récompense et appliquez des algorithmes d’apprentissage par renforcement. Ajustez au besoin.
- Évaluation et Déploiement : Testez le modèle avec des requêtes réelles ou simulées. Évaluez les améliorations de performances, puis déployez le modèle affiné dans votre environnement de production.
Conclusion et Prochaines Étapes
En tant que développeur explorant les grands modèles de langage, comprendre ce qu’est le fine-tuning par renforcement, comment il fonctionne, et le processus complet de fine-tuning peut révolutionner votre approche de développement en IA. Grâce au fine-tuning par apprentissage par renforcement, vous pouvez élever vos modèles au-delà des données d’entraînement statiques pour créer des expériences interactives offrant des réponses plus précises, adaptées au contexte et alignées sur les attentes des utilisateurs.
Le pouvoir transformateur du RFT s’étend à divers secteurs, qu’il s’agisse de la santé, des services financiers, du droit ou du développement logiciel. Que vous recherchiez des exemples de fine-tuning pour vous inspirer ou que vous exploriez le fine-tuning de modèle pour une tâche spécialisée, envisagez d’intégrer le RFT à vos méthodes. Cette approche non seulement aligne le comportement de votre modèle sur les attentes humaines, mais permet aussi de maintenir des cycles d’entraînement fluides et rentables.
Appel à Action : Vous êtes prêt à essayer ? Expérimentez avec des ensembles de données réduits, affinez un modèle simple, et appliquez les principes du RFT dans votre flux de travail. Suivez les améliorations et partagez vos expériences avec la communauté. Comment le raisonnement de votre modèle a-t-il évolué après l’application de l’apprentissage par renforcement ? Laissez un commentaire ci-dessous ou contactez-nous pour toute question. Vos idées pourraient inspirer d’autres développeurs à entamer leur propre voyage « Jour 2 ».
Les meilleurs jours de votre grand modèle de langage sont à venir. Adoptez le RFT et transformez-le en un atout spécialisé, parfaitement adapté à vos besoins uniques.